So we decided to buy a house, what will the journey look like?
There are plenty of easily-googlable resources on the house buying process in Canada and in Québec more specifically (here’s the two most detailed I’ve seen: FCAC and CMHC), so I won’t try to repeat that information, but I’ll document the specifics of our process which will invariably result in a brief outline of the steps to follow.
Roughly what we’ll try to do:
Get a relatively good family income so we can qualify for a reasonable mortgage loan.
Build up a credit history.
Save up for a down payment.
We’ve worked on those first three steps since we moved to Canada: I’ve been fortunate enough to have a stable and well-paid job, which has allowed us to use consumer credit responsibly, so should have a pretty good rating. It also allowed us to save for a down payment. So at this point we should be ready for the next parts of the process:
See a lender to get financially checked and pre-approved for a loan. You can go for a well-known financial institution, perhaps your bank, or you can go to a mortgage broker, which is what I’m planning on doing.
Once you know your price range, you can start looking at houses in your desired areas.
BUT before you can start with this, you should know roughly how much you can afford, be realistic with your inputs and use one of the available online calculators. I like this one which will tell you how much you should be able to afford, and this one which calculates your estimated payments. And this one is very simple but also very detailed as to the criteria used to estimate affordability. It makes sense to use this so you’re not disappointed when the broker tells you you can only afford a tiny shack in the boondocks :).
You should also have a pretty good idea of whether you like your target neighbourhood. Montreal is a geographically large city and neighbourhoods can differ, so it makes sense to check the ones you like and make a short list. If you don’t care where you buy, there’s something for almost any price range, but I don’t think that’s very common.
A possible problem with the neighbourhood you like is whether you can afford it. If you can’t just yet, there are two options: choose a different one or get more money (higher salary, larger down payment).
Once I identified our target neighbourhoods, I started scouring centris.ca frequently, looking for houses in (and out of) our price range, checking their pictures and prices, nearby amenities, and comparing several possible neighbourhoods. We ended up discarding one of those, even though it was cheaper and had more inventory, because we decided we didn’t really like it that much. So we’re focusing on one of the other candidates, and also looking at adjacent neighbourhoods, which can be cheaper while still being closer to the amenities we want.
OK, so knowing how much we can afford (per the calculators) having located (and lived in) a neighborhood we like and knowing the approximate price range for homes here, and knowing it is within our affordability, I’m ready to hit the mortgage broker.
Weechat used to require some weird perl scripts to trigger on specific conditions, but since version 1.1 (from 2014) a trigger plugin can do all that without needing an external script.
This will create a trigger that runs a command when a specific word (or words) is mentioned in any channel you’re on:
/trigger addreplace warningword signal *,irc_in2_PRIVMSG "${message_without_tags} =~ (danger will robinson|stop the line|help me)" "" "/exec -bg /usr/bin/paplay /usr/share/sounds/ubuntu/notifications/Positive.ogg
---- name:Run a local task hosts:127.0.0.1connection:localtasks: - name:loop the loopuri:url:http://www.someurl.example.com/status.htmlreturn_content:yesregister:foountil:foo.content.find("monkeys") != -1delay:1retries:5
The task can be whatever you want: I used uri but it’s more usually shell or something like that. The main thing is that you need to use register so you’ll have something to check in the until: condition.
We mocked it like this, to be able to pass an actual list of expected values the function will iterate over:
importmockmock_journal=mock.Mock()mock_journal.__next__=mock.Mock(side_effect=[1,2,3,4])mock_journal.__iter__=mock.Mock(return_value=mock_journal)foriinmock_journal:print(i)# I don't call any methods in mock_journal, but I could,# :and could then assert they were called.
So mock_journal is both a mock proper, where methods can be called (and then asserted on), and an iterable, which when called repeatedly will yield elements of the __next__ side_effect.
Recently I ran into a script which tried to verify HTTPS connection and response to a specific IP address. The “traditional” way to do this is (assuming I want http://example.com/some/path on IP 1.2.3.4):
This is useful if I want to specifically test how 1.2.3.4 is responding; for instance, if example.com is DNS round-robined to several IP addresses and I want to hit one of them specifically.
This also works for https requests if using Python <2.7.9 because older versions don’t do SNI and thus don’t pass the requested hostname as part of the SSL handshake.
However, Python >=2.7.9 and >=3.4.x conveniently added SNI support, breaking this hackish way of connecting to the IP, because the IP address embedded in the URL is passed as part of the SSL handshake, causing errors (mainly, the server returns a 400 Bad Request because the SNI host 1.2.3.4 doesn’t match the one in the HTTP headers example.com).
The “easiest” way to achieve this is to force the IP address at the lowest possible level, namely when we do socket.create_connection. The rest of the “stack” is given the actual hostname. So the sequence is:
Open a socket to 1.2.3.4
SSL wrap this socket using the hostname.
Do the rest of the HTTPS traffic, headers and all over this socket.
Unfortunately Requests hides the socket.create_connection call in the deep recesses of urllib3, so the specified chain of classes is needed to propagate the given dest_ip value all the way down the stack.
After wrestling with this for a bit, I wrote a TransportAdapter and accompanying stack of subclasses to be able to pass a specific IP for connection.
There are a good number of subtleties on how it works, because it messes with the connection stack at all levels, I suggest you read the README to see how to use it in detail and whether it applies to you need. I even included a complete example script that uses this adapter.
If juju1 and juju2 are installed on the same system, juju1’s bash auto completion breaks because it expects services where in juju2 they’re called applications.
Maybe juju2 has correct bash completion, but in the system I’m working on, only juju1 autocompletion was there, so I had to hack the autocomplete functions. Just added these at the end of .bashrc to override the ones in the juju1 package. Notice they work for both juju1 and juju2 by using dict.get() to not die if a particular key isn’t found.
# Print (return) all units, each optionally postfixed by $2 (eg. 'myservice/0:')_juju_units_from_file(){python -c '
trail="'${2}'"
import json, sys; j=json.load(sys.stdin)
all_units=[]
for k,v in j.get("applications", j.get("services",{})).items():
if v.get("units"):
all_units.extend(v.get("units",{}).keys())
print "\n".join([unit + trail for unit in all_units])
'<${1?}}# Print (return) all services_juju_services_from_file(){python -c '
import json, sys; j=json.load(sys.stdin)
print "\n".join(j.get("applications", j.get("services",{}).keys());'<${1?}}
So today I woke up to beautiful “Hacked by…” top posts, as well as modifications to existing posts in my blogs. It’s entirely my fault for not promptly upgrading to WordPress 4.7.2, so I was vulnerable to this:
Picadillo is a traditional Mexican recipe, usually made with minced meat. Seitan, however, makes a great substitute for minced meat, and since most of picadillo’s flavor comes from the sauce and reduction process, the flavor stays mostly similar.
Mince the seitan: Chop it into small dice, then run in small batches through a food processor on high, until you get a size similar to cooked, minced meat.
Prepare the sauce: Put the tomatoes, garlic and broth in the blender, blend for 1 minute or until smooth.
Do the thing: On a large (5L or more) pot, fry the onion with the olive oil until transparent. Once fried, dump the seitan, potato and carrot dice in the pot, dump the sauce and stir (it should initially look like a stew – if it’s drier, make some more sauce and add it to the pot). Set the heat to medium-high, bring the mixture to a boil and let simmer until the liquid is consumed and the carrots and potatoes are soft. BEWARE, there’ll come a point where you will need to start stirring to avoid burning the bottom part of the stew. This will happen even if the top seems to have enough liquid, so keep an eye on it. It should take 20-25 minutes to evaporate the sauce to the desired consistency.
When done, stir in the already-cooked green peas (so they remain firm, if you cook them in the stew they’ll go mushy).
Serve with white or red rice, or with corn tortillas.
I’m working on adding some periodic maintenance tasks to a service deployed using Juju. It’s a standard 3-tier web application with a number of Django application server units for load balancing and distribution.
Clearly the maintenance tasks’ most natural place to run is in one of these units, since they have all of the application’s software installed and doing the maintenance is as simple as running a “management command” with the proper environment set up.
A nice property we have by using Juju is that these application server units are just clones of each other, this allows scaling up/down very easily because the units are treated the same. However, the periodic maintenance stuff introduces an interesting problem, because we want only one of the units to run the maintenance tasks (no need for them to run several times). The maintenance scripts can conceivably be run in all units, even simultaneously (they do proper locking to avoid stepping on each other). And this would perhaps be OK if we only had 2 service units, but what if, as is the case, we have many more? there is still a single database and hitting it 5-10 times with what is essentially a redundant process sounded like an unacceptable tradeoff for the simplicity of the “just run them on each unit” approach.
We could also implement some sort of duplicate collapsing, perhaps by using something like rabbitmq and celery/celery beat to schedule periodic tasks. I refused to consider this since it seemed like swatting flies with a cannon, given that the first solution coming to mind is a one-line cron job. Why reinvent the wheel?
The feature that ended up solving the problem, thanks to the fine folks in Freenet’s #juju channel, is leadership, a feature which debuted in recent versions of Juju. Essentially, each service has one unit designated as the “leader” and it can be targeted with specific commands, queried by other units (‘ask this to my service’s leader’) and more importantly, unambiguously identified: a unit can determine whether it is the leader, and Juju events are fired when leadership changes, so units can act accordingly. Note that leadership is fluid and can change, so the charm needs to account for these changes. For example, if the existing leader is destroyed or has a charm hook error, it will be “deposed” and a new leader is elected from among the surviving units. Luckily all the details of this are handled by Juju itself, and charms/units need only hook on the leadership events and act accordingly.
So it’s then as easy as having the cron jobs run only on the leader unit, and not on the followers.
The simplistic way of using leadership to ensure only the leader unit performs an action was something like this in the crontab:
* * * * * root if [ $(juju-run {{ unit_name }} is-leader) = 'True' ]; then run-maintenance.sh; fi
This uses juju-run with the unit’s name (which is hardcoded in the crontab – this is a detail of how juju run is used which I don’t love, but it works) to run the is-leader command in the unit. This will print out “True” if the executing unit is the leader, and False otherwise. So this will condition execution on the current unit being the leader.
Discussing this with my knowledgeable colleagues, a problem was pointed out: juju-run is blocking and could potentially stall if other Juju tasks are being run. This is possibly not a big deal but also not ideal, because we know leadership information changes infrequently and we also have specific events that are fired when it does change.
So instead, they suggested updating the crontab file when leadership changes, and hardcoding leadership status in the file. This way units can decide whether to actually run the command based on locally-available information which removes the lock on Juju.
The solution looks like this, when implemented using Ansible integration in the charm. I just added two tasks: One registers a variable holding is-leader output when either the config or leadership changes:
The second one fires on the same events and just uses the registered variable to write the crontabs appropriately. Note that Ansible’s “cron” plugin takes care of ensuring “crupdate” behavior for these crontab entries. Just be mindful if you change the “name” because Ansible uses that as the key to decide whether to update or create anew:
- name:create maintenance crontabstags: - config-changed - leader-elected - leader-settings-changedcron:name:"roadmr maintenance - {{item.name}}"special_time:"daily"job:"IS_LEADER='{{ is_leader.stdout }}'; if [ $IS_LEADER = 'True' ]; then {{ item.command }}; fi"cron_file:roadmr-maintenanceuser:"{{ user }}"with_items: - name:Delete all fooscommand:"delete_foos" - name:Update all barscommand:"update_bars"
A created crontab file (in /etc/cron.d/roadmr-maintenance) looks like this:
A few notes about this. The IS_LEADER variable looks redundant. We could have put it directly in the comparison or simply wrote the crontab file only in the leader unit, removing it on the other ones. We specifically wanted the crontab to exist in all units and just be conditional on leadership. IS_LEADER makes it super obvious, right there in the crontab, whether the command will run. While redundant, we felt it added clarity.
Save for the actual value of IS_LEADER, the crontab is present and identical in all units. This helps people who log directly into the unit to understand what may be going on in case of trouble. Traditionally people log into the first unit; but what if that happens to not be the leader? If we write the crontab only on the leader and remove from other units, it will not be obvious that there’s a task running somewhere.
Charm Ansible integration magically runs tasks by tags identifying the hook events they should fire on. So by just adding the three tags, these events will fire in the specified order on config-changed, leader-elected and leader-settings-changed events.
The two leader hooks are needed because leader-elected is only fired on the actual leader unit; all the others get leader-settings-changed instead.
Last but not least, on’t forget to also declare the new hooks in your hooks.py file, in the hooks declaration which now looks like this (see last two lines added):
Finally, I’d be remiss not to mention an existing bug in leadership event firing. Because of that, until leadership event functionality is fixed and 100% reliable, I wouldn’t use this technique for tasks which absolutely, positively need to be run without fail or the world will end. Here, I’m just using them for maintenance and it’s not a big deal if runs are missed for a few days. That said, if you need a 100% guarantee that your tasks will run, you’ll definitely want to implement something more robust and failproof than a simple crontab.
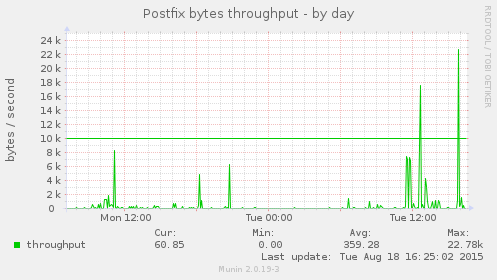
I had a hell of a time configuring Munin to send out e-mail alerts if values surpass specific thresholds. Many of the articles I found focused just on setting up the email command (which was the easy part), while few told me *how* to configure the per-service thresholds.
Once the thresholds are configured, you’ll see a green line for the warning threshold and a blue line for the critical one, like in this graph:
Some of Munin’s plugins already have configured thresholds (such as disk space monitoring which will send a warning at 92% usage and a critical alert at 96% or so). But others don’t, and I wanted to keep an eye on e.g. system load, network throughtput and outgoing e-mail.
The mail command can be configured in /etc/munin-conf.d/alerts.conf:
contact.myname.command mail -s "Munin ${var:group} :: ${var:host}" thisisme@somewhere.com
Next in /etc/munin.conf, under the specific host I want to receive alerts for, I did something like:
This will send alert if the postfix plugin’s volume surpasses 100k, if the load plugin’s load values surpass 1.0 or 5.0 (warning and critical, respectively) and if df plugin’s _dev_sda1 value is over 60% (this is disk usage).
Now here’s the tricky part: How to figure out what the plugin name is, and what the value from this plugin is? (if you get these wrong, you’ll get the dreaded UNKNOWN is UNKNOWN alert).
Just look in /etc/munin/plugins for the one that monitors the service you want alerts for. Then run it with munin-run, for example, for the memory plugin: