Protecting French
by Roadmaster
“Vote for change. Vote Conservative”.
Are they serious right now? Ya’ll know “Conservative” means “opposed to change and progress”, right?
Remember the isolated, gray, inconsequential country Canada was becoming under Stevie here. It takes a lot of gall and a huge bet that people have no historic memory, to paint him and the party as the harbingers of change for the better.

Seriously can’t make this stuff up. Is he even serious? Literally cooying Donnie? It’s like he’s not even trying anymore. Still, stay vigilant so this clown-ass doesn’t get elected because he’s a danger not only to Canada but to the entire planet.
Poilievre promises to scrap single-use plastics ban and bring back the plastic straw
Conservative leader follows Trump’s February executive order banning paper straws across government
I’ve been working on a project that uses sqlalchemy for database abstraction and as I was finding out how to express queries with sqlalchemy, a thought struck me:
All these query DSLs look really cool: sqlalchemy, Django ORM, Prisma, Phoenix/Ecto, Rails ActiveRecord. Some allow you to express relational entities as objects and classes and to issue queries by composing functions. Others are lower-level and have a more direct mapping to SQL statements (e.g. sqlalchemy or Ecto) but still use features native to your language that are then mapped to SQL operations.
Over the years I’ve seen two main issues with these database access libraries and I’m finally ranting and crystallizing them in a couple of thoughts.
First, ORMs abstract developers from the intricaces of the underlying data storage engine. This is a good thing because it allows them to just use the data store with no learning curve, right? The problem comes when coders don’t think about what’s underneath. It’s easy to assume you’re just creating objects and calling methods on them, but each of these operations has a cost. Countless stories about developers assuming method calls for related collections are free, searches are just RAM dictionary lookups and you can query by any of an object’s attributes at no extra cost, and then getting bitten by the fact that you have a relational DB underneath, are very common. My usual saying is that a developer must absolutely know the features, properties, antipatterns and best practice of the database anyway.
Second, unless you’re literally only ever going to code in a single language, those db abstraction libraries are more of a hindrance. If I’m jumping between Python, Ruby and Elixir projects I have to learn and keep current with sqlalchemy or Django ORM, ActiveRecord, and Ecto, each with their distinct syntax to express queries. If only there was a single common language with which to express RDBMS operations… guess what? it’s called SQL!
I think it’s likely beneficial to just use raw SQL queries for all but the most trivial of operations (and even then: I can more easily remember how to write a SELECT statement than how to express that in three different ways via native libraries). Most of those libraries have an easy way to take the result of a query and map that back to domain objects if you prefer to use those.
Another benefit is that it’s then very easy to switch database libraries; I was using raw aiosqlite in a project and it was fairly easy to switch to sqlalchemy while still using the queries I’d written for aiosqlite.

“Poilievre says he’ll use notwithstanding clause to ensure multiple-murderers die in prison” <- Here he is again suggesting cancellation of people’s most fundamental rights and use that as a justification to eliminate (literally kill) those he deems undeserving. You just need to revamp the justice system, not use the nuclear notwithstanding clause at a Federal level to non-person murderers - but it’s of course an easy target because multiple murders raise ires and are entirely undefensible, right?
The clause is bad enough when used at a provincial level, there’s no justification for using it at the federal level.
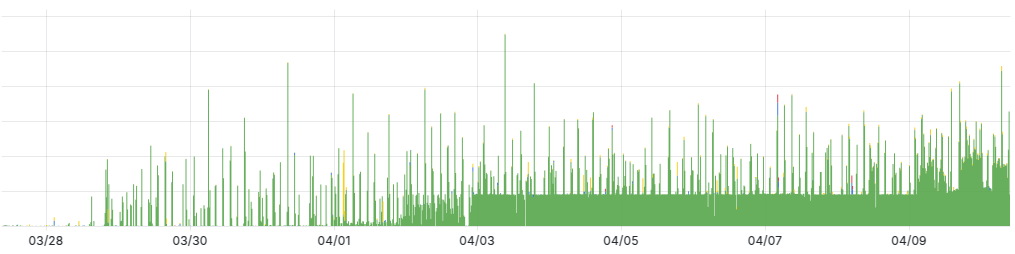
I stood up a simple server with nepenthes. I put a link to it in an existing web page (I won’t say which one). In less than 2 weeks this server is handling about 1000 requests/hour, that’s about 20,000/day. This all comes from bots. By far the worst offender is Amazonbot.
{
"ag": "Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)",
"hits": 1719
}
{
"ag": "Mozilla/5.0 (compatible; AwarioBot/1.0; +https://awario.com/bots.html)",
"hits": 20596
}
{
"ag": "Mozilla/5.0 (compatible; SemrushBot/7~bl; +http://www.semrush.com/bot.html)",
"hits": 2912
}
{
"ag": "Mozilla/5.0 (Linux; Android 7.0; SM-G892A Build/NRD90M; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/60.0.3112.107 Mobile Safari/537.36",
"hits": 11
}
{
"ag": "Mozilla/5.0 (compatible; MJ12bot/v1.4.8; http://mj12bot.com/)",
"hits": 96187
}
{
"ag": "Mozilla/5.0 (compatible; MJ12bot/v2.0.0; http://mj12bot.com/)",
"hits": 3103
}
{
"ag": "Mozilla/5.0 (compatible; DotBot/1.2; +https://opensiteexplorer.org/dotbot; help@moz.com)",
"hits": 16
}
{
"ag": "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36",
"hits": 174659
}
{
"ag": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1",
"hits": 89
}
An octopus has tentacles. So two octopuses have twentycles? :)
These videos I want to encode have:
I want to convert that to something my old Roku can play. I only care about those three streams. Video should be 8-bit h264, audio should be ac3.
ffmpeg -i original.mkv -map 0:0 -map 0:2 -map 0:5 -c:v libx264 -crf 18 -vf format=yuv420p -c:a ac3 output.mkv

When they make you wait 3 years for the next 5 episodes in a show.
me, sometimes: “Sorry, that screenshot tells me nothing”. Also me, sometimes: “Sorry, that tells me nothing. Send me a screenshot.”